


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Onodera, Naoyuki; Idomura, Yasuhiro
Lecture Notes in Computer Science 10776, p.128 - 145, 2018/00
Times Cited Count:10 Percentile:85.61(Computer Science, Artificial Intelligence)We developed a CFD code based on the adaptive mesh-refined Lattice Boltzmann Method (AMR-LBM). The code is developed on the GPU-rich supercomputer TSUBAME3.0 at the Tokyo Tech, and the GPU kernel functions are tuned to achieve high performance on the Pascal GPU architecture. The performances of weak scaling from 1 nodes to 36 nodes are examined. The GPUs (NVIDIA TESLA P100) achieved more than 10 times higher node performance than that of CPUs (Broadwell).
Shimokawabe, Takashi*; Endo, Toshio*; Onodera, Naoyuki; Aoki, Takayuki*
Proceedings of 2017 IEEE International Conference on Cluster Computing (IEEE Cluster 2017) (Internet), p.525 - 529, 2017/09
Stencil-based applications such as CFD have succeeded in obtaining high performance on GPU supercomputers. The problem sizes of these applications are limited by the GPU device memory capacity, which is typically smaller than the host memory. On GPU supercomputers, a locality improvement technique using temporal blocking method with memory swapping between host and device enables large computation beyond the device memory capacity. Our high-productivity stencil framework automatically applies temporal blocking to boundary exchange required for stencil computation and supports automatic memory swapping provided by a MPI/CUDA wrapper library. The framework-based application for the airflow in an urban city maintains 80% performance even with the twice larger than the GPU memory capacity and have demonstrated good weak scalability on the TSUBAME 2.5 supercomputer.
Matsumoto, Kazuya; Asahi, Yuichi*; Ina, Takuya; Idomura, Yasuhiro
no journal, ,
We present the implementation and performance evaluation results of the plasma physics simulation code called GT5D on a GPU cluster. In this study, an iterative matrix solver, which is identified as a performance bottleneck in the code, is tuned on the GPU. The measured performance is compared with attainable performance calculated by the roofline model. Additionally, we show the implementation with direction communications between GPUs for utilizing many GPUs.
Onodera, Naoyuki; Idomura, Yasuhiro
no journal, ,
Since diffusion simulations of pollutants attract high social concern, high-precision and real-time analysis is required. We developed a CFD code based on LBM (Lattice Boltzmann Method) with AMR (Adaptive Mesh Refinement). In this presentation, we propose optimum data structure and calculation algorithm for real-time LBM analysis.
Onodera, Naoyuki; Idomura, Yasuhiro
no journal, ,
A real-time simulation of the environmental dynamics of radioactive substances is very important from the viewpoint of nuclear security. We develop a CFD code based on a Lattice Boltzmann Method (LBM) with a block-based Adaptive Mesh Refinement (AMR) method. The code is tuned to achieve high performance on the latest Pascal GPU architecture. By introducing a temporal blocking technique, the number of the MPI communications is significantly reduced.
Ina, Takuya; Idomura, Yasuhiro; Imamura, Toshiyuki*; Yamashita, Susumu; Onodera, Naoyuki
no journal, ,
We have developed mixed-precision preprocessing for the preconditioned conjugate gradients (PCG) method in the multi-phase multi-component thermal-hydraulic code JUPITER. The preconditioner employs a hybrid mixed-precision approach which combines FP16 data and FP32 operations. The roundoff errors are reduced by converting FP16 data to FP32 on cache, holding the intermediate result in FP32, converting the final result to FP16, and returning it to the memory. The developed preconditioner was tested for large-scale problems with 3D structured grids of 3,200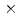 2,00014,160. The convergence of the PCG method was maintained even when the FP16 data format was used for ill-condition matrices, and the computational speed was dramatically increased by reducing the memory access. The hybrid FP16/32 mixed-precision implementation achieved 1.79 speedup from the FP64 implementation at 2,000 nodes on Fugaku.
2,00014,160. The convergence of the PCG method was maintained even when the FP16 data format was used for ill-condition matrices, and the computational speed was dramatically increased by reducing the memory access. The hybrid FP16/32 mixed-precision implementation achieved 1.79 speedup from the FP64 implementation at 2,000 nodes on Fugaku.
